A/B Testing Search: thinking like a scientist
In our last installment, we learned about the important of metrics and how the choice of metrics is so important to building, maintaining, and improving our search system. In today’s episode, we’ll be discussing where the rubber meets the road of search relevance improvement: experimentation (aka A/B testing, aka split testing, etc)
Experimentation, in my mind, is what separates the Data Scientist from a Machine Learning Engineer. A brief primer on experimentation: experimentation is a controlled method of testing a hypothesis. A hypothesis is an educated guess, sure, but it’s also a guess that can be measured. It’s your line in the sand that says “if my theory about how people use my service is right, then I’ll see this result” and “if I’m wrong, then I need to update my theory”. This will be important later.
A good hypothesis might look like:
Because I see[insert data/feedback from research]
I expect that [change you’re testing] will cause [impact you anticipate] and
I’ll measure this using [data metric]
(adapted from https://www.shopify.com/blog/the-complete-guide-to-ab-testing)

Science is the foundation of all knowledge, and experimentation is the bedrock of science. An experiment controls for variables outside the scope of what you are testing. What we mean by that is we try to exclude the effects of time, types of users, types of tasks, or types of queries from our analysis, so that we can see the real cause of a change in our metrics.
Let’s take an example: suppose we are rolling out a new search algorithm that gives better relevance on natural language queries, and we show it to all of our users starting on Monday morning. However, unbeknownst to us, the marketing team sent out an email on Monday morning that implored users to try our new natural language search. What do you think might happen? A bunch of users might come to the site and use natural language query terms and we might see an increase in our metrics. We’d be happy 😊 but we’d be wrong 😢. We would not be able to attribute the increase in natural language searches to our change in the algo or the marketing email!
Likewise there are so many, many things that could change the metrics of our search engine from day-to-day: changes in user demographics, new inventory, day-of-the-week effects, and on and on.
So, how do we control for these external sources of variability (aka noise)? Run an experiment. At its simplest, we would run our experiment by giving half of our users the old version of the search algorithm and half would get the new version. To ensure that we haven’t introduced bias into our experiment, we will randomly assign users to one treatment or the other. The random assignment will ensure that whatever variability exists in our user population it will be represented in our samples, equally. [Of course, it’s more complicated than that, but let’s not make things more difficult than they need to be, okay? Okay]
Once we have our theory, our hypothesis, our samples, and we have our metrics, we need to run the experiment and collect some data. Here’s where experiments for search can be a bit … different.
Most experiments you run on websites will focus on things like “conversion rates” or other user/session level metrics. However, with search, every query is a new trial, a new chance to succeed or fail. There are different types of queries, too, so you might succeed with some and fail with others.
The first question you have to ask yourself about your queries is “are they different?” For our analysis, we only care about queries that would have been different in control than in the treatment. For that we need counterfactual logging — a way of understanding what would have been different in the other branch of the experiment. This is not super easy, but it is very useful.
If we start an experiment for Natural Language queries, and put 1/2 of our users into treatment and 1/2 into control and we measure which are “happy” (blue faces), we get the same 37.5%. Was our experiment a wash?

Well, no. If we look at people who actually issued a natural language query (red faces), we can see the overlap (purple) is different. Actually 2x the natural language queriers in treatment were happy! That’s dilution, the washing out of experimental results by looking at too broad a set of data.
(This section shamelessly stolen from Andrea Burbank’s talk at qcon 2014 https://www.infoq.com/presentations/ab-testing-pinterest#downloadPdf )
To fight against dilution, we have to log the counterfactual. We have to understand that this query would have gotten different search results if it had been in the other treatment. There are a few ways to do this. We could run the queries offline and examine the results. This is time consuming, and there are potential errors. We can also run queries against both algorithms at run time and only show the results of one algo to the user, that is quite accurate, but it doubles the load on the search infrastructure. The third approach, which we take at LexisNexis is to drop a “handled” flag when the query traverses certain nodes of the search algorithm “tree”. How this works is if we have an algorithm that looks for a natural language query with 4 or more words, a query like “dog bite” is natural language, but does not have 4 words. A query like “foo /s bar” is Boolean, so it’s not handled. A query like “contract renewal service specification” is natural language and has 4 or more terms.

It doesn’t guarantee that we are only getting changed queries, but it’s efficient and accurate enough to make good decisions.
One advantage of using handled queries is that it enables us to look at a particular subset of queries, which increases the statistical power of our experiment.
The next thing that makes search experimentation different is the segmentation of queries. I’ve hinted at it above with Boolean vs natural language queries, but there are dozens of ways to segment queries depending on your industry and user tasks. Some of the more common ones are:
- Natural Language- queries expressed in a human way
- Boolean- syntax involving terms and connectors like AND, OR, NOT, and special operators. Typically this is only used in professional settings, but many search engines still support special characters and operators. Even Google.
- Navigational- a query designed to get a user to a specific location, product, or document, e.g. “cnn” to get to cnn.com from Google
- Specific- a query with a clear intent, such as “how to run a linear regression in pyspark” the intent is clear, but the searcher doesn’t want a particular location.
- Broad- a query with unclear intent that may span multiple categories, e.g. “spiderman” on Amazon — does the searcher want movies, comics, t-shirts, or pajamas?
- Ambiguous- a query with a couple of likely specific intents. The canonical example of an ambiguous query is “stiletto” — does the user want a knife or a shoe (or recently a hammer or false fingernails)?
There are many other ways to categorize queries, these are just a few examples. And they can be combined in fun and interesting ways, too! You could have a broad natural language query or an ambiguous Boolean query.
The categorization of queries is important, because as you look at the results of your A/B test, you might see some types of query are improved and some are harmed by the new version of the algorithm. To figure out which is best you’ll have to run your analysis against each classification of query that you care about. Then you have to look at the metrics and make a judgement call. Maybe broad natural language queries were improved, but ambiguous Boolean queries were negatively impacted… it’s up to you to evaluate the tradeoff. Generally, we go for the algorithm that does the greatest amount of good for the largest number of queries, but that might not be the case for your site. You may have strategic reasons to favor one class of queries or users. Keep all this in mind as you are analyzing the results of your experiment.
Speaking of analysis …
What kind of analysis are you going to run? Different analyses can provide quite different results, and you need to understand the implications before you fire up R or Python and start throwing around metrics.
Often, analysis is done at the individual query level. This can give us significant statistical power, as there are usually more queries than users running queries (I’m not sure how you could have more users running queries than queries, but maybe it’s possible). However, that may not take into account the bias stemming from different user types. Maybe some users are just more likely to issue harder queries? Maybe some are more likely to do broad searches? There are myriad ways that users can be different, so one of the techniques that I advocate is using a Linear Mixed Effects model (LME) an LME is a method for taking into account the effect of user differences AND the effect of time.
Time rears its head in all sorts of ways in an experiment, from novelty effects to regression to the mean. A novelty effect is a positive effect on a metric because something has changed. Maybe we started adding a cake recipe to the top of our search results. People may interact with our cake recipe a great deal initially, because they are curious, but soon interaction will decrease as people get used to the cake recipe and don’t get value from it.
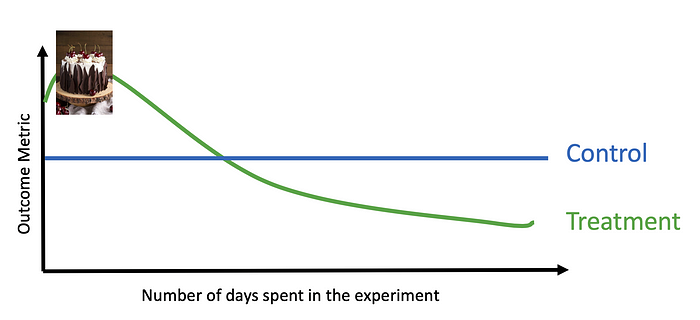
The inverse of a novelty effect is a learning effect where it takes time for people to become aware of a new feature or learn its value. In search this can manifest as trust. It takes time for users to trust that the system will be able to accurately respond to a certain kind of input.
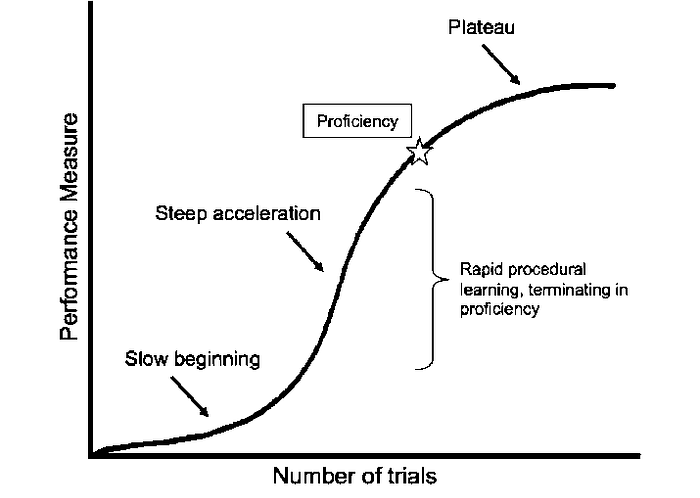
Regression to the mean is another interesting time-based effect that crops up in experiments. Regression to the mean is the concept that outliers, positive or negative, will naturally move back to the mean of the population over time. I’ll let Veratisium give you more detail…
So there are distinct time-based effects to experiments. Therefore, when we do our analysis, it’s important to take time into account. The first step is to align our users based on the number of days they’ve actually been in the experiment. This way it doesn’t matter if the experiment has run for 30 days, if it’s the user’s second day seeing the test, they have two “days in” the experiment. Aligning users on days-in lets us build a model of usage over time, helping us to avoid the regression to the mean and novelty effects because we can see the effects of time without new users joining the experiment. What we really care about, in the end, is how much better our new algorithm will be over the long haul.
This is what an LME does for us. We align our metrics by the number of days the user has been in the experiment, and look for changes over time. What’s really fun is that we can even look at the users’ past behavior and add that to the model. This lets us know we are having a direct impact on that user.
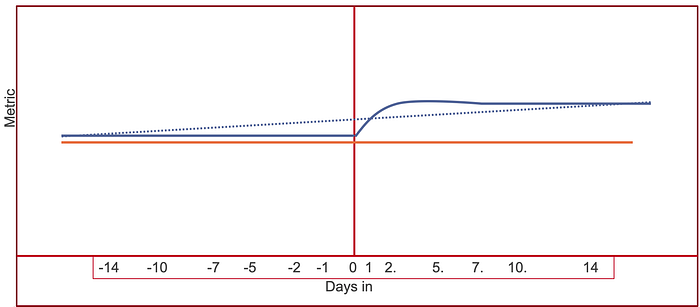
The reason this is so important is that even with good sample sizes, we can still end up with a biased sample. What if our users in the treatment just had higher <metric> to begin with?
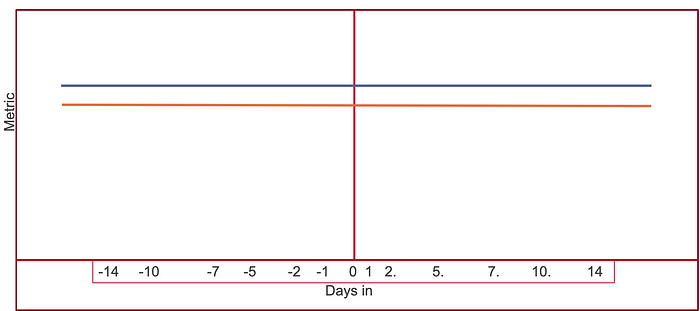
Of course, you don’t have to make user-based analyses or use an LME to try to remove bias. You could just do an ANOVA that is pre-post, looking at the metrics before/after the experiment began at the query level. A pre-post ANOVA is quicker and easier than a Linear Mixed-Effects model, but it will get you a lot of the “goodness”. Doing a query-based analysis means that your analysis will be tilted towards your power users who issue more queries. Nothing wrong with that, but it’s something to consider. Do we improve the average user’s experience or are we improving the average query? Depends on your goals.
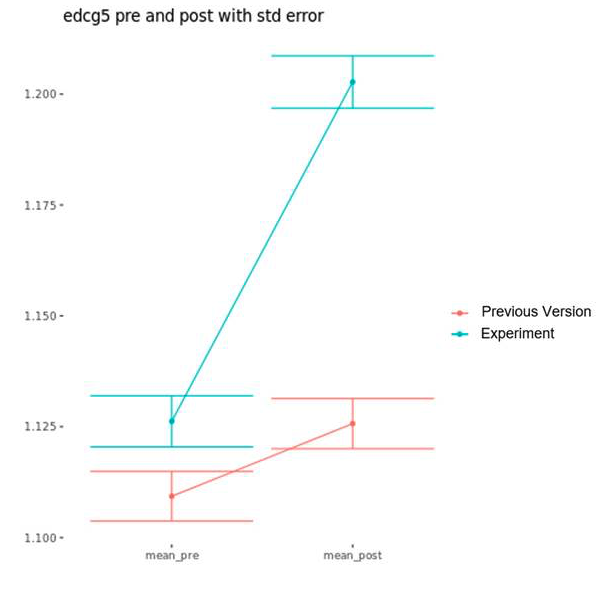
Of course, the fly in the ointment with either of these methods is that you need some data from before the experiment begins. What do you do if you don’t have users that come back frequently enough to get a good read on the data over time? Well you could only use experiment data, excluding the “pre” data, but you might get a biased sample. Increasing your sample size should help reduce that risk. However, there is another contender for king of the search analysis throne …
Enter Interleaved Testing. Interleaving is an experimental methodology where individual users are shown both variants of an algorithm by interleaving the results.
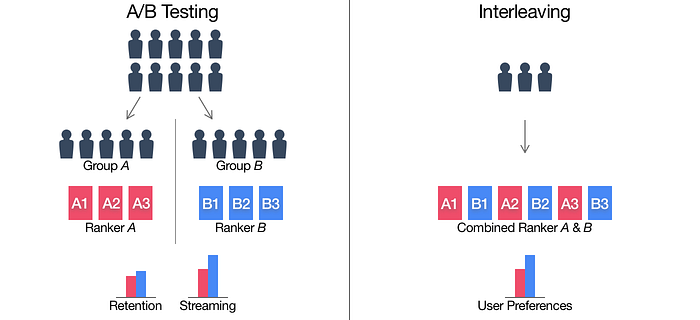
By interleaving the results, we are now showing a single user a superset of the results of A and B, then we can simply allow them to engage with the search results and measure their preference. The measurement of preference is important here because it means that there is no difference in time, task, or user bias. Each trial of the test happens in that moment, with the same user performing the same task. Because of this, statistical power goes through the roof.
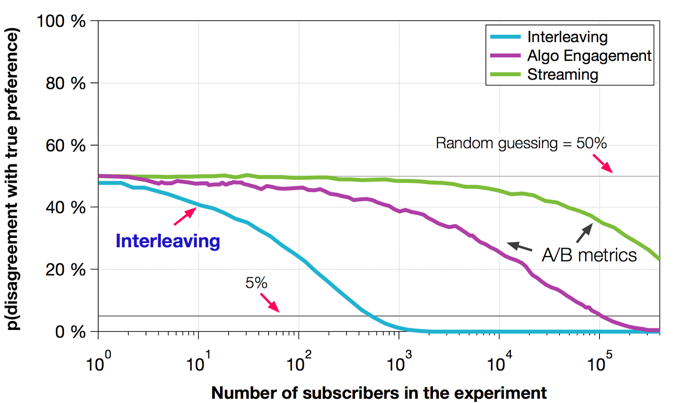
There are a lot of nuances to performing good interleaved tests, which I will studiously sidestep and provide some links. https://www.cs.cornell.edu/people/tj/publications/chapelle_etal_12a.pdf
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/fp041-schuthA.pdf
https://www.slideshare.net/o19s/the-right-path-to-making-search-relevant-taxonomy-bootcamp-london-2019?next_slideshow=1
and of course https://netflixtechblog.com/interleaving-in-online-experiments-at-netflix-a04ee392ec55
Interleaving represents probably the best approach to gathering statistically significant results quickly and with the fewest tradeoffs. However, that doesn’t mean that we can get huge data in a day or two and “ship it” — time effects such as novelty and regression to the mean still apply, so it’s important to run experiments for long enough to ensure that the results are meaningful and long-lasting.
Hopefully, this gives you some sense of the scope of A/B testing search. It’s important to think like a scientist: control your variables, develop measurable hypotheses, user the right methodology, and apply the appropriate statistic to draw valid conclusions. Once you have done so, it’s time to learn some useful lessons about your test and use that as fuel for future improvements.